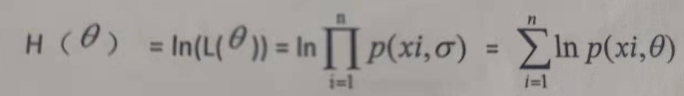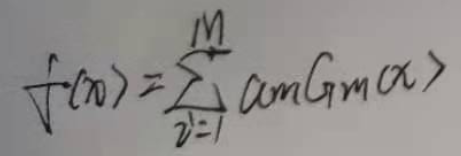引言
MobileNet–2017年谷歌提出的专注于移动端和嵌入式设备的轻量级cnn架构。
随着人工智能的发展,cnn架构已经在计算机视觉领域取得了长足的进步。例如在每年的imagenet分类问题上,可以看到为了追求更高的精准度,研究者们提出的模型越来越深,也越来越复杂,例如残差神经网络–ResNet的层数已经达到了152层。

- 但是在某些情境下,例如嵌入式和移动端设备下,这样庞大的复杂模型是难以落到实际应用的。模型过于庞大,内存要求就非常高,移动端和嵌入式设备明显无法满足。其次,在这些设备场景要求下的延迟要低,反应速度要快,因此过大过复杂的cnn模型显然无法复用。
- 尽管未来的硬件速度会越来越快。但是数据处模型本身的轻量化研究也是必不可少的。因此,目前小而高效且适用于嵌入式和移动端环境的cnn架构研究至关重要。
- 目前,轻量化的cnn模型研究主要分为两个方向,一个是将训练好的模型压缩得到小模型。二是直接设计小模型并进行训练。但无论何种设计思路,其基本目标都是在保证模型性能的前提下降低模型的大小,同时提高模型的反应速度。
- MobileNet就是goole研发的一种小而巧的cnn模型,他属于两个研究方向的后者,其在accuracy和latency之间做了折中。
深度可分离卷积(Depthwise separable convolution–DSC)
MobileNet的基本单元是深度级可分离卷积,顾名思义,他是一种可分解卷积,主要包括两个部分的操作–深度卷积和节点卷积(depthwise convolution和pointwise convolution)
1,深度卷积:如图1所示,深度卷积和标准卷积不同,标准卷积的卷积核是用在所有的输入通道上,而深度卷积每个输入通道对应一个卷积核,每个书输入通道采用的卷积核是独立的,不相互影响。
2,节点卷积:节点卷积和普通的卷积核没什么差别,只不过其采用了1 * 1的卷积核而已,图2清晰的展示了两种操作。
3,对于dsc,其工作过程是首先是深度卷积对每一个输入通道进行卷积,然后采用节点卷积对上面的结果进行结合。这样其实整体效果和一个标准卷积是差不多的,但是会大大减少计算量和模型参数量。


4.dsc和标准卷积的差别
假定输入特征图大小: D(k)*D(k)*M
假定输出特征图大小:D(F)*D(F)*N
M , N是指通道数, 我们假定输入和输出的宽和高是一致的,所以有
标准卷积的计算量:D(F)*D(F)*M *D(F)*D(F)*N
depthwise convolution其计算量为: D(K)、D(K)、M、D(F)、D(F)
对于 pointwise convolution计算量是:M、N、D(F)、D(F)
所以depthwise separable convolution总计算量是:
D(K)、D(K)、M、D(F)、D(F) + M、N、D(F)、D(F)
可以比较depthwise separable convolution和标准卷积如下:

一般情况下比较大,那么如果采用3x3卷积核的话,depthwise separable convolution相较标准卷积可以降低大约9倍的计算量。其实,后面会有对比,参数量也会减少很多。
MobileNet的一般结构
上面讲到,dsc是mobile的基本组件,但在实际的应用中会加入batchnorm,并使用relu去线性。所以其基本结构如下


mobilnet的结构图如上图所示:
1,首先是一个标准的3 * 3 卷积,然后后面就是堆积dsc,可以看到其中部分深度级卷积会通过stride =2来进行downsampling.
2,然后采用average pooling将feature map 大小改为1,然后进入全连接层,最后softmax
3,如果单独只算深度卷积和节点卷积, 那么整个网络有28层(这里Avg Pool和Softmax不计算在内)
4,我们还可以分析整个网络的参数和计算量分布,如表2所示。可以看到整个计算量基本集中在1x1卷积上

MobileNet 瘦身:降低通道和每个特征图的大小
mobilenet基础之上我们如何进行进一步模型轻量化呢,那就是引入两个超参数,第一个参数就是width multiplier,主要是按比例减少通道数,记为α,其取值范围为(0,1],那么输入和输出的通道数将变成系数和,因此dsc的计算量(参数量)为:
第二个参数 是resolution multiplier,主要是按比例降低特征图的大小,记为p,加上resolution multiplier,dsc的计算量为:

引入超参数p只会影响计算量,不会改变参数量。但是瘦身肯定会带来mobile整体性能的下降,但总体结果往往都是在精确度,模型大小,计算量之间折中。
MobileNet的TF实现:
可参考git文章详情